[리뷰] 심층 강화학습 인 액션
in Review on Review, Book, 심층학습, 강화학습, 몬테카를로, 마르코프, Dqn, 행위자-비평자, 진화, 호기심, 다중에이전트, 주의모형, 관계모형, Openai, Gym

제이펍출판사의"심층 강화학습 인 액션(알렉스 짜이, 브랜던 브라운 공저 / 류광 역)"를 읽고 작성한 리뷰입니다.

강화 학습(Reinforcement Learning)은 환경 안에서 에이전트가 현재의 상태를 인식하여 선택 가능한 행동들 중 보상을 최대화하는 행동을 선택하는 방법이다. 알파고 그 중에서도 특히 알파고 제로의 경우가 좋은 예제라 할 수 있다.
강화학습은 배울 것이 너무 많고 하나하나 난이도 끝판왕급의 지식들로 이루어져 있기에 배우기 어렵다. 수학과 기본 지식을 어느정도 통달하지 않고서는 원서나 논문 중심으로 지식을 학습한다는 것은 불가능에 가깝다.
결국 한글로 쓰여진 책들의 도움이 간절한데 안타깝게도 한글로 강화학습을 다루는 책은 매우 드물다. 강화학습을 익혀 나만의 알파고를 구현하고자 시중의 서적을 모두 구매하여 보유하고 있었는데 일부 훌륭한 책도 있으나 조금씩 아쉬운 부분도 있었다. 그런데 최근에 들어 반갑게 본 도서를 만날 수 있었다.
이 책의 큰 장점 중 하나로 국내 서적 중 유일하게 강화학습의 최신 연구 성과를 다룬다는 점을 들 수 있다. 6장에서는 CartPole에 유전 알고리즘을 적용하는 코드를 구현하고, 8장은 ICM(Intrinsic Curiosity Module, 내재적 호기심 모듈)을 다룬다. 심지어 10장에서는 주의 및 관계 모형을 적용하여 XAI를 시도하기까지 한다.
강화학습의 기본에 충실하기도 급급한 처지이지만 개인적으로 한단계 뛰어넘는 최신 성과들을 접해보기라도 하고 싶었는데 이 책이 가려운 구석을 긁어주어 얼마나 시원했는지 모른다. 아직 모든 것을 정확히 이해한다고 자신할 수는 없지만 유전 알고리즘을 구현하는데 크게 어렵지 않았기에 절반의 성과는 거둔셈이라 스스로 위안을 삼고 있다. 보다 새로운 기법에의 접근을 가능하게 해준 이 책에 매우 고마움을 느낀다.
수학을 열심히 공부했고 좋아하지만 고수라고 감히 말할 수는 없는 입장에서 그나마 최신기술의 맛을 볼 수 있었던 이유는 이 책 덕분인데 책에 어떤 특징이 있어 가능했는지 설명하는 것이 이 책을 읽을 독자분들께 도움이 될 것이라 생각하여 간단히 정리해 본다.
우선 이 책은 제목에서 알 수 있듯 유명한 “in Action” 시리즈 중 하나이다. 인 액션 시리즈는 IT, AI 영역을 가리지 않고 대부분 양서들로써 일단 구현을 할 수 있는 역량을 키워주는데 매우 적합한 책이다.
이런 특징때문에 독자 각자의 처지에 따라 책의 호불호가 갈릴 수는 있겠지만 기본적으로 이 책을 읽어본 독자라면 양서에 가깝다는 판단에는 대부분 동의할 것으로 생각한다.
만약 새로운 것을 창조해야 하는 연구자라면 이 책은 조금 부족할 것이다. 연구자가 아니라 잘은 모르겠지만 이 책에는 수식이 많이 등장하지만 여타 전공 서적에 비하면 수식이 적은 편이다.
대신 연구보다는 구현을 목적으로 하는 엔지니어라면, 또 빠른 시간내에 구현을 필요로 한다면 이 책은 가뭄의 단비보다 소중한 책이다. 지금 내 처지가 그렇다. 언제까지 강화학습의 기본 지식만 학습하거나 처음부터 수식을 들여다보기에는 너무 많은 시간이 필요하다. 개인적인 목표는 스스로 알파고를 구현하는데 있기에 필요 이상의 기초 지식을 원하지는 않는다.
이 책은 인 액션 시리즈 답게 하나씩 따라하다보면 구현을 통해 내부 메커니즘을 이해할 수 있는 구조로 되어 있어 구현 실력을 끌어올리는데 큰 도움이 되었다.
그렇다고 수학없이 코드로만 구성된 책도 아니다. 코드는 수학과 메커니즘을 이해하기 위한 의사소통 수단으로 쓰였을 뿐 그 자체가 목적이 되지는 않는다. 책에서도 언급하기를 수학 없이 강화학습을 익히는 것은 마치 부실공사에 가까운 기초가 허약한 상태에서 예제 코드를 흉내내는 이상의 의미를 부여하기 어렵다는 식으로 무의미함을 밝힌다. 개인적으로도 수학을 배제한 책이 얼마나 훌륭할까라는 생각이 들어 언젠가 부터는 수식이 등장하지 않으면 즐겨보지 않게 되었다.
그렇다면 이 책은 수식이 존재하는데 어떻게 수식을 이해시키고 구현 능력을 향상시켜 주는 것일까? 저자의 전달력도 한 몫 했겠지만 무엇보다도 큰 도움이 되었던 몇가지 독특한 방식이 있었기에 구체적으로 소개해보려 한다.
난이도와 타임라인의 방향 일치
이게 무슨 말인가 하면 강화학습의 최초 기원으로 거슬러 올라가 최신 기술에 이르기 까지 시간 순으로 설명하는 방식을 취하고 있다는 의미이다. 먼저 간단한개념을 소개하고, 문제를 마주치며, 해결책을 고민하고, 해법을 고안하며, 시험하고, 개선하다가 형식화하고, 수학 공식 등으로 정리하는 순서를 지킨다.대부분의 기술 서적은 거꾸로 현재의 기술을 정의, 소개하고 필요한 경우에만 과거의 히스토리를 잠깐 언급하기에 기억력외에 우리 두뇌 능력을 활용하기 어렵게 구성되어 있는데, 저자는 통찰력 있게 그 부분의 맹점을 해소하고자 노력하였다. 그 흐름 속에서 자연스럽게
구체화된 예시를 종종 만날 수 있기에 이해하기 너무 편하다는 느낌을 받을 수 있었다.
수식과 의사코드
먼저 예시를 통해 살펴보자. 아래 그림은 Q 학습 알고리즘의 갱신 규칙에 대한 수식인데 처음 이 수식을 만났을때의 황당함을 떠올리면 이런 친절한 책이 또 있나 싶을 정도다.
먼저 해당 수식을 소개하기 전에 충분히
개념과 줄글로 설명을 한 후,수식이 등장하면 위 사진이 보여주듯 각 애매모호한기호를 하나씩설명해준다. 그럼에도 이해 못할 경우를 대비하여의사코드로 구현해보고, 이에 대한 설명으로 이해의 쐐기를 박는다.그래도 부족할 것 같은 부분에는
Python 코드로 설명을 한다. 아래 그림은 기대 보상에 근거하여 최선의 동작을 선택하는 방법을 수식, 의사코드, Python 코드로 표현한 예제이다.
이러한 장점 때문에 구현에는 자신이 있는데 수식에 자신이 없는 사람이라면 이 책이 제 격이라 할 수 있다.
끈 그림(String Diagram)
이 역시 예시로 먼저 설명하는 것이 빠를 듯 하다.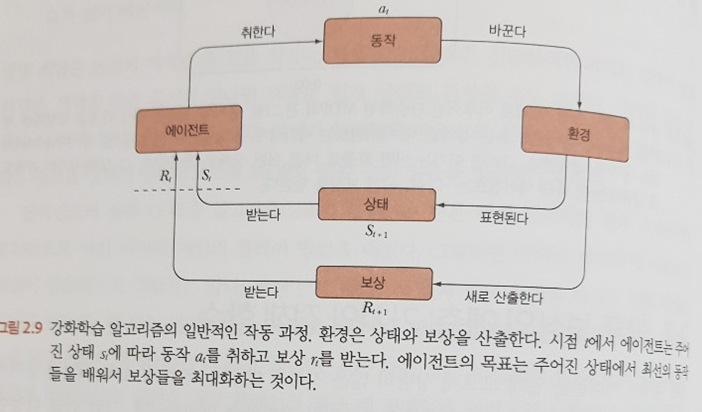
기존 강화학습 서적들을 보면 강화학습의 시작에는 늘 이와 같은 그림이 등장한다. 그런데 자세히 보면 약간 다르다는 것을 알 수 있다. 선(끈)에는 화살표가 있고 주로
동사에 해당하는 부분이 기술되어 있고, 네모 박스 안에는명사에 해당하는 부분이 기술되어 있다.상태와 동작을 명확히 나눠줌으로써 명확한 이해를 돕는다. 강화학습의 기본 메커니즘이 복잡해질수록비슷한 용어가 무수히 쏟아진다. 상태 공간, 동작 공간, 상태 가치, 동작 가치, 정책 함수, Q 함수, Q 학습, 심층 Q 신경망 등 이 용어들을 명확하게 이해하지 못하면 강화학습 메커니즘을 이해하는 것이 불가능한데 끈 그림의 적절한 역할 분리가 내게는 큰 도움이 되었다. 그동안 애매모호했던 개념들이 확실해지면서 구현하는데 애로사항이 크게 줄어들었다.
OpenAI의 Gym
최근 GPT-3로 화제를 모았던 OpenAI에서는 강화학습을 위한 기막힌 환경을 제공하는데 이를 Gym이라 한다. 링크에 접속해보면 지원하는 환경들이 나오는데 기본적인 알고리즘부터, 아타리, 로봇제어 문제와 같은 다양한 유형의 환경들이 제공된다.강화학습을 연구하는 입장에서 이를 적용할 게임을 만들라고 한다면 그 자체로 비효율적인 또 하나의 과제가 주어지는 셈인데 이런 환경이 제공됨으로써 부수적인 것들은 걷어치우고
강화학습 구현에만 집중할 수 있다.본 도서는 아래 사진과 같이 다양한 형태로 Gym을 효율적으로 사용한다. 첫번째 그림은 ICM을 적용한 슈퍼마리오 예제이고, 두번째 그림은 분포 DQN을 적용한 아타리 예제이다.

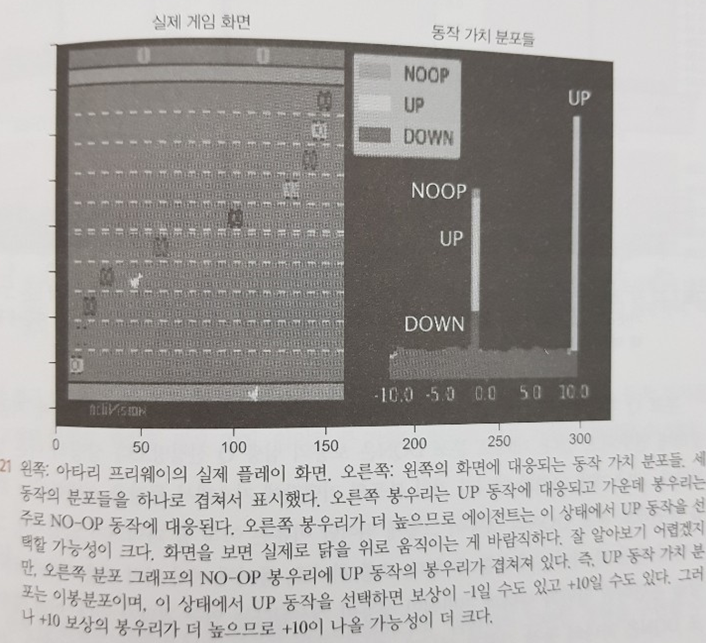
위와 같이 본 도서에는 학습 능률을 높혀주는 다양한 장치들이 소개되어 있다. 더불어 관련 논문을 집대성 한 후 구현 우선 중심으로 취사선택하여 완급을 조절하고 있기에 참 잘 만들어진 책이라는 생각을 했다.
개인적으로 바둑을 즐겨했고 그 안에 숨은 미묘한 감이 정량적으로 계산될 수 있다는 희망을 갖고 있었기에 이를 확인하고자 나만의 알파고를 만들기 위해 꾸준히 노력해 왔다. 여담으로 알파고를 만드는 일에 관심이 있다면 아래 리뷰들을 참고하면 된다. 이 책들 또한 알파고 뿐만 아니라 강화학습을 실전적으로 배우는 데 많은 도움이 되는 양서들이다.
이 책 덕분에 나만의 알파고 구현에 한 걸음 더 가까이 다가갈 수 있게 되었다.
더불어 번역의 질도 우수하다. 역자가 번역의 매끄러움을 위해 곳곳에 노력한 티가 보인다. 다만 일반적으로 흔히 쓰이지 않는 단어로 번역된 경우도 보인다.
예를 들면 learning rate는 보통 학습율로 번역이 되곤 하는데 본 도서에는 학습 속도라는 명칭으로 번역을 했다. 이런 부분들 때문에 때로는 생소한 느낌이 들긴 하지만 어차피 원어가 아닌 이상 보다 명확한 해석이 가능하다면 잠시 다른 시각으로 바라봄으로써 되려 전달력이 향상될 수 있는 장점도 있다.
다중 슬롯 머신을 굳이 여러 팔 강도라는 표현으로 번역한 것도 재미있는데 이런 큰 차이가 있는 부분은 역주로 따로 번역의 주를 달아놓았기에 전체적으로 이해하는데 무리는 없었다. 일반적인 서술 문구는 번역의 품질이 훌륭했다고 본다.
정리하자면 본 도서는 논문의 이해 혹은 구현을 목표로 하는 이에게 가장 적합한 책이라는 생각이 든다. 물론 초보 연구자들 또한 연구에 앞서 구현을 해보는 것이 깊은 이해에 도움이 될 것이다. 마찬가지로 고급의 문을 열고 더 높은 곳으로 나아가려는 이들에게도 이 책이 최신 기술의 입문서 역할을 충분히 수행할 수 있을 것이라 생각한다. 특히, 강화학습에 어려움을 겪는 이에게 강력히 추천하고 싶다.
